3 week
- Neural Machine Translation with Sequence-to-Seqeunce
- NMT Basics
- Intermediate NMT
- Advanced Topic in NMT
Review
- 언어모델(language model)이란 무엇인가
- 문장의 확률을 모델링 하는 것
- 기존
- 수식으로 풀어보기
- 확률을 모델링 하는 것은 이전 단어가 주어졌을 때, 다음 단어를 예측하는 것 (체인룰)
- Marcov Assumption에서는 앞에 조금만 보더라도 예측을 할 수 있음
- 굳이 다 볼 필요가 없음
- corpus에서 해당 word sequence가 나타나는지의 출현 빈도를 가지고 계산 할 것
- 모든 word sequence로 하면 힘듬
- Marcov Assumption으로 n-gram사용
- 여전히 문제 : 확률이 0이 아닌데 여러 문제로 0으로 나옴
- 대처 :Smoothing, discounting, back-off, interpolation
- 대처를 했음에도 해결이 안됨
- 수식으로 풀어보기
- Neural Network
- Generalization이 뛰어남
- unseen word sequence에 대처가 가능
- 고양이와 개가 얼마나 비슷한지 계산 할 수 있음
- 애완동물과 반려동물 얼마나 비슷한지 계산 할 수 있음
- 굳이 exact한 word sequence를 일부분밖에 보지 못하였더라도 Neural network는 word embedding을 해서 vector를 만들었기 때문에 어떻게든 구할 수 있음
- Neural Network이전에는 값이 나오지 않았음
- NN은 이렇게 되지 않을까?라고 추측하는데 잘 틀리지도 않음
- unseen word sequence에 대처가 가능
- auto-regressive
- 과거 자신의 값을 참조해서 현재 자신의 값을 추론
- 언어 모델은 auto-regressive함
- Cross-Entropy를 가지고 비교함
- x와 x^의 차이로 인해 직접적인 비교는 하지 않음
- Perplexsity를 minimize하는게 LM의 목표였는데, cross-entropy의 exponential이 ppl임
- Classification은 Cross-Entropy, Regression은 MSE
- 한 단어단어 매 타임스탭을 classification 하는 것
- Inference Mode는 Training Mode와 다름
- Teacher Forcing으로 인해
- 기존에 잘 되지만, 아쉬움
- SMT와는 확연한 차이가 있음
- 실제 구현
- 훈련용 및 테스트용 모델이 다르게 있어야 함
- Training Method와 Inference Method의 차이가 생김을 기억
- Generalization이 뛰어남
- n-gram vs neural network
- n-gram
- memory 많이 필요 - table
- query만 날리면 됨
- 보기가 주어졌을 때 확률을 고를 때 n-gram
- neural network
- memory 적게 필요 - weight만 있으면 됨
- 계산을 계속 해야되서 느림
- 문장을 만들어낼 때와 같은 경우 neural network 사용
- n-gram
Neural Machine Translation with Sequence-to-Seqeunce
NMT Basics
Objective
- 번역 : 불어가 주어졌을 때, 영거가 나올 확률 분포
- 번역기 : 확률 분포를 최대로 하는 문장을 뽑아내는 것
History
- 1950’s 부터 시작
- Rule-based MT (RBMT)
- Neural network보다 더 띄어난 generalization 능력이 있는 사람은 규칙을 가지고 번역이 가능
- 언어 쌍마다 규칙을 만들어줘야 함
- Statistical MT (SMT)
- 통계기반으로 감 (규칙 필요 없음)
- 언어학자의 도움이 필요 없음
- 구글이 잘했음
- 100개 국어
- rule이 필요없고 corpus만 있으면 되었음
- 통계기반으로 감 (규칙 필요 없음)
- Phrased based MT (PBMT)
- WMT에서 NMT의 주목
Why? (Why NMT is better?)
- End-to-end 모델
- 성공적인 generalization
- Discrete한 단어를 continuous한 값을 변환하여 계산
- Language Model의 고도확
- Context embedding
- 기존에 불가능한 embedding을 embedding 시킴
- LSTM과 Attention의 적용
- Sequence의 길이에 구애 받지 않고 번역
- 기본 SMT는 submodel이 결합되어 단계 단계로 이뤄짐
- 에러가 전파됨 (error propagation)
- SMT는 Unseen word sequence 불가 (n-gram 영향)
- 바닐라 RNN의 한계
Seqeunce to Sequence
- Encoder = source sentence = 문장을 하나의 점으로 압축하는 것
- Decoder = 점을 받아서 문장을 만드는 것
- Embedding = Discrete -> continuous로 변경
- Generator = vector를 continuous -> Discrete 변경
- 기본에는 Encoder만 가능
- AutoEncoder
- Encoder와 Decoder가 있음
- AutoEncoder로 해석 가능
- 실제 Sequence한 AutoEncoder로 해석 가능
- 일반적인 AutoEncoder와 다른 점
- 입력과 출력이 다름
- 정보는 같음 -> 같은 정보 (색상 반전정도)
- Encoder와 Decoder가 있음
n개의 단어가 있는 입력 문장x와 m개의 단어가 있는 출력 문장y가 있을 때, x-> y가 나올 확률을 최대로 하는 파라미터를 찾는게 목표
MLE(Maximum Likelihood Expectation)로 나옴
MAP(Maximum A Posteriori) 사후 확률을 최대로 하는 게 목표인데, Neural Network를 훈련하는 건 MLE임
Encoder
- 문장을 점으로 만듦 (vector)
- I love to go to school이라는 분포가 있을 것
to
해석
- prev time step의 hidden state를 current time step의 emb word를 RNN에 넣어주면 current time step의 hidden state 값이 나옴
참고 : RNN이 여러개 층이면, RNN의 출력은 마지막 layer의 hidden state가 출력이 됨- concatination
- 0 부터 끝까지를 표현
Text Classification과 다를 것이 없음 : 점을 만드는 것(text classification은 점을 만들어 긍정, 부정)
Decoder
- = Language Model
- Conditional Neural Network Language Model
- Source sentence가 주어지고 이제까지 뱉어낸 단어가 주어졌을 때, 현재 값을 구함
- 어떠한 조건이 주어졌을 때, 어떠한 문장이 나올 확률인 것임
- Contidition RNNLM
Sequence to Sequence
- Decoder의 Initial hidden state는 Encoder의 Last hidden state
to
- 상기는 EOS를 띤 것 : Y[:-1]
-
임베딩 레이어 통과
- 점을 글자로 만드는 작업
Generator
- 한마디로 softmax
- hs는 hidden size이며 이는 총 단어의 size가 되어야지 원하는 y값이 나옴
Applications
| Se2seq Application | Task (From-To) |
|---|---|
| Neural Machine Translation (NMT) | 특정 언어 문장을 입력으로 받아 다른 언어의 문장으로 출력 |
| Chatbot | 사용자의 문장 입력을 받아 대답을 출력 |
| Summarization | 긴 문장을 입력으로 받아 같은 언어의 요약된 문장으로 출력 |
| Other NLP Task | 사용자의 문장 입력을 받아 프로그래밍 코드로 출력 등 |
| Automatic Speech recognition(ASR) | 사용자의 음성을 입력으로 받아 해당 언어의 문자열(문장)으로 출력 |
| Lip Reading | 입술 움직임의 동영상을 입력으로 받아 해당 언어의 문장으로 출력 |
| Image Captioning | 변형된 seq2seq를 사용하여 이미지를 입력으로 받아 그림을 설명하는 문장을 출력 |
Concolusion
- Seq2seq is an Autoencoder for sequential data which provides a transition between domain to another domain
- Limitation
- Memorization
- Lack of Structural Information
Intermediate NMT
Attention
- Atttention = Key-Value function with differentiable
Key-Value Function
1
dic = {'computer': 9, 'dog': 2, 'cat'}
Differentiable Key-Value function
- 유사도를 리턴
- 유사도는 cosine similarity 혹은 dot product로 구할 수 있음
- word2vec에 대해 유사도에 대한 query를 날리는 것과 비슷
Attention
- Query : 현재 time-step의 decoder output
- Keys : 각 time-step 별 encoder output
- Values : 각 time-step 별 encoder output
- Context_vector = attention(query=decoder_output, keys=encoder_outputs, values=encoder_outputs)
How it works
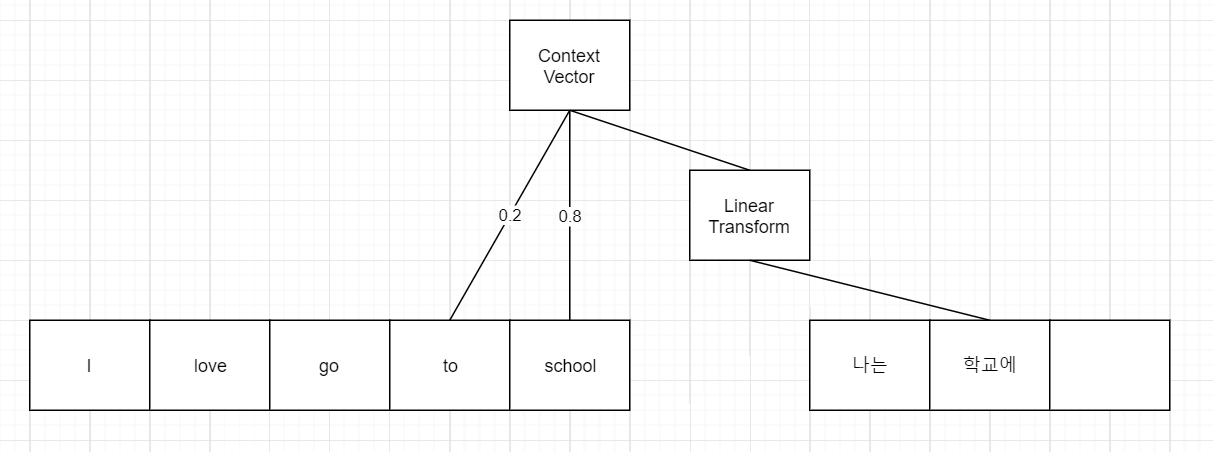
- Attention = key, value function
- 똑같지 않아도 유사도(proxy)로 리턴
- weighted sum
- 임베딩 방법에 따라서 차이가 남
- Attention은 query를 날리는 것
- 현재 상황에서 질문을 하는 것
- 질문을 하는 방법은 무엇인가?
- Attention은 Linear Transformation, 즉 질문하는 방법을 배우는 것임
Linear Tranformation
- 2개의 case간의 유사도가 있다고 하고 맵핑을 함
- 배워야하는 것
- 한국어와 영어가 다르니 당연히 Linear Transformation이 있어야 함
- Linear Transformation은 backpropagation을 통해서 배움
- optimal한 weight가 있으면 아무리 길어도 가능
Attention
- current time step의 hidden state
- W is learnable parameter
- hidden state X W
- dot product는 유사도
- w는 softmax를 취했으니 0~1사이 값이 나옴
- w에 대한 가중합을 하면 c가 나옴
- c와 hidden size가 concatenation 함 “;”
- linear transformation을 한 후 rnn처럼 tanh를 실행
-
Where $hs$ is hidden size of RNN, and $ V_{tgt} $ is size of output vocabulary.
Evaluation
- Attention을 하면 성능이 떨어지지 않음
Variations of Attention
- Additive Attention
- 여러가지 Attention이 있음
Input Feeding
- h tilde가 나오면 softmax에서 one hot vector가 됨
- one hot은 정보의 손실이 생김
- 정보의 손실을 줄이기 위해 embeding vector에 softmax이전의 값을 concatenating함
- 구현의 문제
- 이전
- 내부적으로 Cuda가 동작 : parallel
- Input Feeding
- for문으로 sequencial하게 동작
- 이전
Seq2Seq and Attention
Get tensor size
Auto-regressive and Teacher Forcing
- Auto-regressive
- 과거의 자신의 값을 참조하여 현재의 값을 추론(또는 예측)
Because of Teacher Forcing
- There is a difference between training method and inference method
Evaluation
- PPL 및 BLEU가 좋아짐
Search
- Path Search
- Sampling
- Greedy Search
- Beam Search
- 1개만 하는 것이 아닌 K개에서 최선을 구함
- 속도에 제한이 적고 (병렬) 더 좋은 성능을 도출
- Beam Search
Beam Search Implementation
- 누적 확률을 구함
Search
- Ancestral Sampling
- Random sampling
- 상용화 불가
- Random sampling
- Beamsearch Chains
- 성능 좋음
- nlp : 10 정도
- asr : 높음
NLL : negative log likelihood
Length Penalty
- $\alpha$ 와 $\beta$ 는 하이퍼 파라미터
Evaluation Overview
- 평가를 해야함
- Intrinsic (manual)
- 정성평가 : 사람이 하는 것, 비쌈, 제일 정확함
- Extrinsic (automatic)
- 정량평가 : 저렴
- BLUE, METEOR
- 번역에 많이 사용
- ROUGH
- summerization에 사용
19:00
Cross Entropy and Perplexity
- PPL = exp(Cross Entropy)
BLEU
- PPL이 번역할 떄 좋은 것은 아님
- Cross-Entropy로 비교하면 더 좋지 않은 것을 좋다고 함
- 단어가 같아야 좋은 것이라고 판단하기 때문
- Cross-Entropy로 비교하면 더 좋지 않은 것을 좋다고 함
- Rouge는 precision을 recall(회수율)로 변경하면 됨
Bi-gram count
- n-gram (여기서는 2개씩)만 맞추면 측정이 됨
Summary for Evaluation Methods
- Perplexity
- Lower is GOOD
- BLUE
- Higher is GOOD
- 미분이 안됨
Consolusion
- Attention
- Finding a “Value” which has similar “Key” to “Query”
- Perplexity (cross-entropy) cannot measure translation quality exactly
Advanced Topic in NMT
Zero-shot Learning
- <2es>
- special token만 넣으면 multi-lingual 훈련이 됨
- 각 언어별로 모델 만드는게 최고
- 그러나 전문분야 도메인에 좋음
- interpolation
Many to One
- 다수의 언어를 encoder에 넣고 훈련
One to Many
- 다수의 언어를 decoder에 넣고 훈련
Many to Many
- 다수의 언어를 encoder와 decoder에 모두 넣고 훈련
Zero-shot Translation
- zero-shot translation 성능 평가
Language Model Ensemble
- monolingual corpus 훈련한 language model과 parrallel corpus를 훈련한 seq2seq를 앙상블 함
- 방법은 여러가지
Back Translation
- 한영 번역기를 만들 때 영한 번역기를 사용하는 것과 비슷
Copied Translation
- 입력에 y를 넣고 출력에 y를 넣으면 됨
Back + Copied Translation
- 목표
- language model을 훈련 (decoder)
- 문장을 많이 볼 수록 decoder의 성능이 좋아짐
- language model을 훈련 (decoder)
Summary of using monolingual corpora
- Language model ensemble
- Pros
- no limit for amount of corpus
- Pros
- Back( + copied) translation
- Pros
- Super-easy
- Both can be used
- Pros
Fully Convolutional Seq2Seq
- pattern 찾는데는 convolution이 좋음
Transformer
- Attention을 여러개를 쌓음
Attention
Positional Encoding
- Since there is not recurrence, we need to put position information by adding positional encoding
Evaluation
- 성능 좋음